经济金融文本分析
课程介绍:
诺奖得主Shiller提出的“叙事经济学”认为,公众预期不仅源于经济数据和理性推断,更广泛受到流行叙事、社会情绪和文化故事传播的影响。因此,经济金融文本数据蕴含着诸多传统结构化数据所缺失的信息,通过剖析新闻报道、社交媒体、政策文件和企业财报等文本资料,研究者能够考察市场情绪、政策不确定性,预测宏观经济指标以及解读投资者心理等。此类分析不仅使经济决策更趋于数据驱动且实时化,而且为政策制定者提供了政策效应评估的崭新工具。
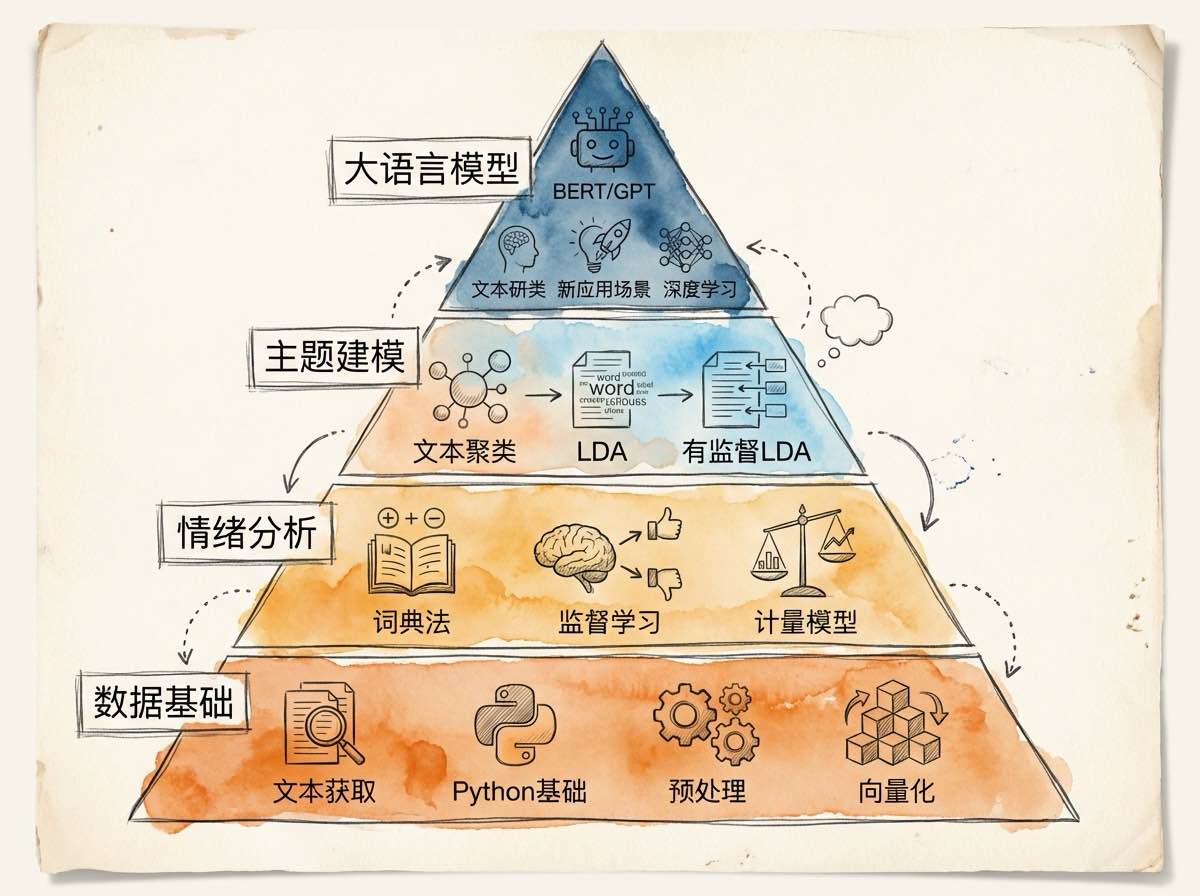
本课程旨在系统讲授如何利用自然语言处理(NLP)技术,从海量财经文本(如上市公司年报、财经新闻、央行沟通、社交媒体)中提取有效信息,并将其转化为可用于经济学实证研究的结构化数据。课程内容涵盖从数据获取到前沿应用的完整流程:首先介绍Python文本爬虫与数据预处理技术;进而深入讲解词向量表示(Word2Vec)、基于词典与计量模型的情绪分析方法、以及文本聚类与主题模型(LDA)。此外,课程紧跟技术潮流,专门探讨大语言模型(BERT/GPT)在文本相似性计算、经济信念模拟及推理中的创新应用。
配套教材:
林建浩等,《经济金融文本分析》,2025,高等教育出版社。
本书全面深入地阐述了文本分析在经济和金融领域的应用,注重计算机科学与人文社会科学——经济学、金融学的相互渗透,为读者提供了系统的学习视角。本书不仅涵盖了文本预处理、情绪分析和主题建模等关键分析维度,还紧跟大语言模型快速发展趋势,详细介绍了深度学习技术及其在经济金融领域的具体应用,使读者能够兼顾基础知识与最新研究动态。通过Python编程实践,本书强化了文本分析理论知识与实际操作的结合,旨在提升读者的经济金融文本分析及实践应用能力。本书适合高等学校经济管理、计算机应用及相关社会科学专业的本科生和研究生作为教材使用,也可作为经济金融从业者的参考用书。
数字化资源地址:https://xuanshu.hep.com.cn/front/book/findBookDetails?bookId=6887ad8ce119ac9729b14912 (高等教育出版社)